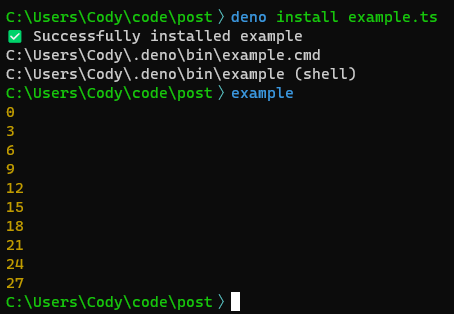
Why Are The URLs So Long?
You might have noticed that URLs for posts in Diskuto are a bit longer than in other systems. For example, the full URL to the previous post about Diskuto is:
URLs for individual posts are in the format:
{baseUrl}/u/{userID}/i/{signature}/
The userID is, of course, the ID of the user that authored the given post. A userID is randomly generated, so reasonably guaranteed to be globally unique. It also happens to be a cryptographic public key.
The signature is a cryptographic signature which, along with the userID can be used to verify the content in question.
Validating Content
Here's an example Deno script that validates the above post:
#!/usr/bin/env -S deno run --check -EN
const baseUrl = `https://blog.nfnitloop.com`
const userID = `A719rvsCkuN2SC5W2vz5hypDE2SpevNTUsEXrVFe9XQ7`
const signature = `4sVxU7pVvUenEdG41BYJDZJfDBZBjBkLSF7dcGzpGMgtVLbZjTh6w5LzC4Rwjkk5SNyn57o3cfsvEbsZJkFELaW3`
// Given these three things, we can validate that the content on the page
// was in fact created by that user, and has not been modified.
import {Client, Signature, UserID} from "jsr:@diskuto/client@0.10.0"
const client = new Client({baseUrl})
const bytes = await client.getItemBytes(userID, signature)
if (bytes == null) {
throw new Error(`No such item on this server.`)
}
// Some helper types for working with cryptography:
const uid = UserID.fromString(userID)
const sig = Signature.fromString(signature)
const valid = await sig.isValid(uid, bytes)
if (!valid) {
throw new Error(`Invalid signature!`)
}
// OK, we have a valid signature for ... some bytes. But is that what's on the page?
// We'll need to inspect the contents of those bytes to verify that the server isn't
// misrepresenting them:
import { fromBinary, ItemSchema } from "jsr:@diskuto/client/types";
const item = fromBinary(ItemSchema, bytes)
console.log(item)
The output of that script shows us the Markdown body that was used to render the given post:
{
"$typeName": "Item",
timestampMsUtc: 1738609806177n,
utcOffsetMinutes: -480,
itemType: {
case: "post",
value: {
"$typeName": "Post",
title: "Diskuto API Release v1.0.0",
body: "<https://github.com/diskuto/diskuto-api/releases/tag/v1.0.0>\n" +
"\n" +
" * Rename to [diskuto-api].\n" +
"\n" +
" * Moved to a new GitHub organization: [Diskuto]\n" +
" \n" +
" * UI has been rewritten and moved into its own repository as [diskuto-web]. \n" +
" Expect most noteworthy changes to happen in this repository moving forward, since\n" +
" the API changes much less often.\n" +
" \n" +
" * New [full-stack] example for local testing.\n" +
" \n" +
" * New OpenAPI schema for the REST API. See: [docs/rest_api/]\n" +
"\n" +
"Breaking API Changes\n" +
"--------------------\n" +
"\n" +
" * The REST API has been relocated to `/diskuto/`. \n" +
" This makes it much easier to serve both [diskuto-api] and [diskuto-web] from one web host.\n" +
" See: [nginx/default.conf] for an example.\n" +
"\n" +
" Note: The old URLs are still available for backward compatibility but will soon be removed.\n" +
"\n" +
" * REST API endpoints have had `/proto3` suffixes removed. \n" +
" These used to be there to distinguish between the HTTP and REST API URLs.\n" +
"\n" +
" * Some REST API paths have been renamed to be more user-friendly. \n" +
" Ex: `/u/` -> `/users/`, `/i/` -> `/items/`.\n" +
"\n" +
" * See [docs/rest_api/] for details.\n" +
"\n" +
"\n" +
"[diskuto-api]: https://github.com/diskuto/diskuto-api\n" +
"[diskuto-web]: https://github.com/diskuto/diskuto-web\n" +
"[Diskuto]: https://github.com/diskuto\n" +
"[full-stack]: https://github.com/diskuto/diskuto-api/tree/main/examples/full-stack\n" +
"[docs/rest_api/]: https://github.com/diskuto/diskuto-api/tree/main/docs/rest_api\n" +
"[nginx/default.conf]: https://github.com/diskuto/diskuto-api/tree/main/examples/full-stack/nginx/default.conf"
}
}
}
Redundancy
Because Diskuto is a peer-to-peer, distributed system, the same content can be hosted on multiple servers. If https://blog.nfnitloop.com ever goes down, or starts blocking users or posts, you can replace the baseUrl with some other server to check whether the content is available there.
And if that server gives you a response, you have the tools to validate that it is in fact the content you were looking for.
Indirection
We could shorten the URLs with some indirection.
We could delegate to some external service to resolve usernames into userIDs. (Ex: a well-known URI, a DNS TXT entry, etc.).
We could allow users to specify slugs for posts.
Those changes might enable us to have URLs like:
https://blog.nfnitloop.com/@diskuto@nfnitloop.com/diskuto-api-release-v1.0.0/
But, using that URL doesn't give us the strong guarantees that the longer URLs do. Imagine that a year or more has passed since that URL was posted to some online forum.
- What if the name-to-id resolution service is down? Or now resolves to some other userID/key?
- What if the server decides to serve some different content under that slug?
We have no way to verify that the linked content is what was there when the link was originally shared.
Making the userID/signature pair part of the URL gives us more tools for finding and verifying content within the distributed system. It lets Diskuto act like a distributed content-addressable store.