Cody Casterline updated their profile.
Cody Casterline updated their profile.
Diskuto!
In my spare time lately, I've been reinvigorated to make some changes to my social network software. No longer "FeoBlog", I've renamed it to "Diskuto", which is Esperanto for "[a] discussion".
The big changes are:
- A new GitHub organization to house the various repositories/tools for working with Diskuto. https://github.com/diskuto
- Separation of UI and API.
- The API server will remain in Rust, but it will no longer come with a bundled UI.
- The UI is now a standalone app, written in TypeScript/Preact, for Deno.
- SSR (server-side rendering) for content.
- Faster to render.
- Better SEO
There's still some work to do for me to consider this "release" done, but I'm already dogfooding it for myself on my personal server. If you're interested to try it out for yourself, let me know!
FWIW, every Item in FeoBlog is cryptographically signed by a key that only the user has, so you can verify that it is unmodified without needing to make another request to a "home" server. See: How Does It Work: #3
Threads's "Federation"
It's the holidays, and you know what that means. … I've had enough time off from programming professionally that now I want to do some of it for fun!
I previously wrote a tool that syncs statuses from Mastodon to my FeoBlog instance. I was thinking about making some updates to that, and then I remembered that I'd read that Threads got around to testing their federation support.
Maybe I can update my tool to also sync posts from Threads, then? Let's test that out and see how their interoperability is coming along. (Spoiler: So far, not great.)
Nushell's built-in support for HTTP requests, JSON, and structured data makes it pretty nice for doing this kind of experimentation, so that's what I'm using here. Let's start by fetching a "status" with the Mastodon REST API:
def getStatus [id: int, --server = "mastodon.social"] {
http get $"https://($server)/api/v1/statuses/($id)"
}
let status = getStatus 111656384454261788
$status | select uri created_at in_reply_to_id
This works, and gives us back (among other data):
╭────────────────┬──────────────────────────────────────────────────────────────────────╮
│ uri │ https://mastodon.social/users/Iamgroot11/statuses/111656384454261788 │
│ created_at │ 2023-12-28T05:26:57.877Z │
│ in_reply_to_id │ 111656368951064667 │
╰────────────────┴──────────────────────────────────────────────────────────────────────╯
So does this, even though that status is coming from a different server. (Yay, federation!)
let status2 = getStatus $status.in_reply_to_id
$status2 | select uri created_at in_reply_to_id
╭────────────────┬───────────────────────────────────────────────────────────────╮
│ uri │ https://spacey.space/users/kmccoy/statuses/111656368910605303 │
│ created_at │ 2023-12-28T05:23:00.000Z │
│ in_reply_to_id │ 111656361314256557 │
╰────────────────┴───────────────────────────────────────────────────────────────╯
We can use the ActivityPub API for retrieving objects from remote servers to confirm that the version we got from our server matches the one published by this user:
def getActivityStream [uri] {(
http get $uri
--headers [
accept
'application/ld+json; profile="https://www.w3.org/ns/activitystreams"'
]
| from json
)}
let remote_status2 = getActivityStream $status2.uri
$remote_status2 | select url published inReplyTo
╭───────────┬──────────────────────────────────────────────────────────────────╮
│ url │ https://spacey.space/@kmccoy/111656368910605303 │
│ published │ 2023-12-28T05:23:00Z │
│ inReplyTo │ https://www.threads.net/ap/users/mosseri/post/17928407810714224/ │
╰───────────┴──────────────────────────────────────────────────────────────────╯
But there's no such luck with Threads. We can fetch the status from mastodon.social:
let status3 = getStatus $status2.in_reply_to_id
$status3 | select uri created_at in_reply_to_id
╭────────────────┬──────────────────────────────────────────────────────────────────╮
│ uri │ https://www.threads.net/ap/users/mosseri/post/17928407810714224/ │
│ created_at │ 2023-12-28T05:15:53.000Z │
│ in_reply_to_id │ │
╰────────────────┴──────────────────────────────────────────────────────────────────╯
But threads.net seems to be misrepresenting that it has an ActivityPub (ActivityStream) object at that URL/URI:
getActivityStream $status3.uri
Error: nu::shell::network_failure
× Network failure
╭─[entry #182:1:1]
1 │ def getActivityStream [uri] {(
2 │ http get $uri
· ──┬─
· ╰── Requested file not found (404): "https://www.threads.net/ap/users/mosseri/post/17928407810714224/"
3 │ --headers [
╰────
I discovered that the URL (not URI) advertises that it is an "activity":
http get $status3.url | parse --regex '(<link .*?>)' | find -r activity | get capture0 | each { from xml }
╭──────┬──────────────────────────────────────────────────────────────┬────────────────╮
│ tag │ attributes │ content │
├──────┼──────────────────────────────────────────────────────────────┼────────────────┤
│ link │ ╭──────┬───────────────────────────────────────────────────╮ │ [list 0 items] │
│ │ │ href │ https://www.threads.net/@mosseri/post/C1YndCeuddr │ │ │
│ │ │ type │ application/activity+json │ │ │
│ │ ╰──────┴───────────────────────────────────────────────────╯ │ │
╰──────┴──────────────────────────────────────────────────────────────┴────────────────╯
… but that URL doesn't serve an Activity either. (It just ignores our Accept header and gives back a Content-Type: text/html; charset="utf-8".)
Summary
So what we seem to have here is Threads doing juuuust enough work to shove ActivityPub messages into Mastodon. But it's certainly not yet supporting enough of the ActivityStream/ActivityPub API to validate against spoofing attacks, as the W3C docs recommend:
Servers SHOULD validate the content they receive to avoid content spoofing attacks. (A server should do something at least as robust as checking that the object appears as received at its origin, but mechanisms such as checking signatures would be better if available). No particular mechanism for verification is authoritatively specified by this document, [...]
Is Mastodon just accepting those objects from a peered server without any sort of validation that they match what that peer serves for that activity? That would allow Threads to inject ads into (or otherwise modify) statuses that it pushes into Mastodon.
Or maybe Threads is only responding to ActivityStream requests if they're coming from a peer server that has been explicitly granted access? That would let them "federate" with peers on their terms, while not letting us plebs peek into the walled garden of data.
I'll reservedly concede that this may just be the current unfinished state of Threads's support for ActivityPub/ActivityStreams. But let's wait and see how much they actually implement, and how interoperable it ends up being.
Cody Casterline updated their profile.
Replace Bash With Deno
I'm starting to get a reputation as a bit of a Deno fanatic lately. But (if you haven't seen the title of this blog post) it might surprise you why I'm such a fan.
If you visit deno.com, the official documentation will tell you things like:
- "Web-standard APIs"
- "Best in class HTTP server speeds"
- "Secure by default."
- "Hassle-free deployment" with Deno Deploy
While all of those are great features, in my opinion the most underrated feature of Deno is that it's a great replacement for Bash (and Python/Ruby!) for most of your CLI scripting/automation needs. Here's why:
Deno is not Bash
Bash is great for tossing a few CLI commands into a file and executing them, but the moment you reach for a variable or an if statement, you should probably switch to a more modern programming language.
Bash is old and has accumulated a lot of quirks that not all programmers will be familiar with. Instead of removing the quirks, or warning about them, they're kept to ensure backward compatibility. But that doesn't make for a great programming language.
For example, a developer might write code roughly like:
if [ $x == 42 ]; then
echo "do something"
else
echo "do something else"
fi
Can you spot the problems?
- if
$xis undefined, the test expression will fail with an error. - if
$xis a string that includes spaces and/or a]character, the tester will likely return an error. - Neither above error stops the script from executing. It is equivalent to the test expression returning "false". You're just going to have unexpected behavior in the rest of your script.
- Worse, some values of
$xmay silently return false positives for this match. (I leave crafting them as an exercise to the reader. Share your favorites!)
These gotchas are even more dangerous when you're writing a script to manage files. Several versions of rm now have built-in protections against accidentally running rm -rf / because it is such a common mistake you can make in Bash and other shells when your variable expansion goes awry.
Do you need an array? As recently as a couple years ago (and possibly even still?) the default version of Bash on MacOS is old enough to not support them. If you write a bash script that uses arrays, you'll get different (wrong) behavior on MacOS.
Seriously, stop writing things in Bash!
Single File Development
My theory is that Bash scripts are the default because people want to just write a self-contained file to get a thing done quickly.
Previously, Python was what I would reach for once a task became unwieldy in Bash. But, in Python you might need to include a requirements.txt to list any library dependencies you use. And if you depend on particular versions of libraries, you might need to set up a venv to make sure you don't conflict with the same libraries installed system-wide at different versions. Now your "single-file" script needs multiple files and install instructions.
But in Deno you can include versioned dependencies right in the file:
import { range } from "https://deno.land/x/better_iterators@v1.3.0/mod.ts"
for (const value of range({step: 3}).limit(10)) {
console.log(value)
}
There is no install step for executing this script. (Assuming your system already has Deno.) The first time you deno run example.ts, Deno will automatically download and cache the remote dependencies.
You can even add a "shebang" to make the script executable directly on Linux/MacOS:
#!/usr/bin/env -S deno run
import ...
While Windows doesn't support shebang script files, the deno install command works on Windows/Linux/MacOS to install a user-local script wrapper that works everywhere.
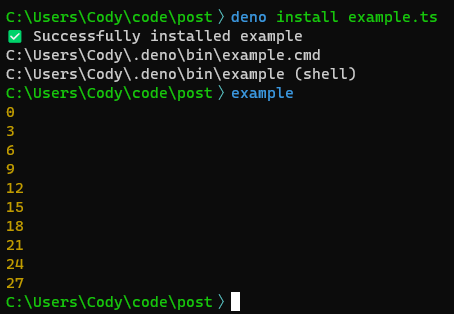
Not only that, you can deno install and deno run scripts from any URL!
deno run https://deno.land/x/cliffy@v0.25.7/examples/ansi/color_themes.ts
But wait, there's more!
Deno makes TypeScript a first-class language instead of an add-on, as it is in Node.js, so the file you write is strongly typed right out of the box. This can help detect many sorts of errors that Bash, Python, Ruby, and other scripting languages would let through the cracks.
By default, Deno leaves type checking to your IDE. (I recommend the Deno plugin for VSCode.) The theory is that you've probably written your script in an IDE, so by the time you deno run it, it would be redundant to check it again. But, if you or your teammates prefer to code in plain text editors, you can get type-checking there as well by updating your shebang:
#!/usr/bin/env -S deno run --check
Now, Deno will perform a type check on a script before executing it. If the check fails, the script is never executed. This is much safer than getting half-way through a Bash or Python script and failing or running into undefined behavior because you typo'd a variable name, or had a syntax error.
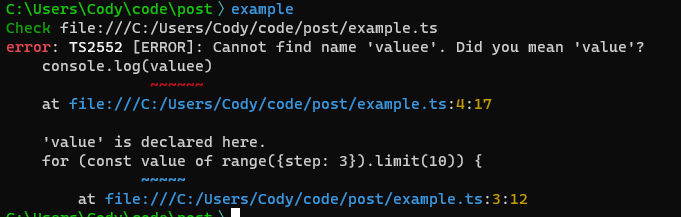
Don't worry, the results of type checks are cached by Deno, so you will only pay the cost when the file is first run or modified.
Summary
While I have not been a fan of JavaScript in the past, Deno modernizes JavaScript/TypeScript development so much that I find myself very productive in it. It's replaced Bash and Python as my go-to scripting language. If you or your team are writing Bash scripts, I'd strongly recommend trying Deno instead!
I forgot about this gem:
You Don't Like Google's Go Because You Are Small
make thousand HTTP(S) requests
D'oh. Make thousands of HTTP(S) requests, that should read.
Golang: (Still) Not a Fan
I try to be pragmatic when it comes to programming languages. I've enjoyed learning a lot of programming languages over the years, and they all have varying benefits and downsides. Like a lot of topics in Computer Science, choosing a language is all about tradeoffs.
I've seen too many instances of people blaming the programming language they're using for some problem when in fact it's just that they misunderstood the problem, or didn't have a good grasp of how the language worked. I don't want to be That Guy.
However, I still really haven't understood the hype behind Go. Despite using it a few times over the years, I do not find writing Go code pleasant. Never have I thought "Wow, this is so much nicer in Go than [other language]." If asked, I can't think of a task I'd recommend writing in Go vs. several other languages. (In fact, part of my reason for finally compiling my issues with Go into a blog post is so I'll have a convenient place to point folks in the future w/o having to rehash everything.)
Before I get into what I don't like about the language, I'll give credit where credit is due for several features that I do like in Go.
Stuff I Like
No Function Coloring
Go doesn't suffer from "Function Coloring". All Go code runs in lightweight "goroutines", which Go automatically suspends when they're waiting on I/O. For simple functions, you don't have to worry about marking them as async, or awaiting their results. You just write procedural code and get async performance "for free".
Defer
Defer is great. I love patterns and tools that let me get rid of unnecessary indentation in my code. Instead of something like:
let resource = openResource()
try {
let resource2 = openResource2()
try {
// etc.
} finally {
resource2.close()
}
} finally {
resource.close()
}
You get something like:
resource := openResource()
defer resource.Close()
resource2 := openResource2()
defer resource2.Close()
// etc.
The common pattern in other languages is to provide control flow that desugars into try/finally/close, but even that simplification still results in unnecessary indentation:
try (val fr = new FileReader(path); val fr2 = new FileReader(path2)) {
// (indented) etc.
}
I prefer flatter code, and defer is great for that.
Composition Over Inheritance
I've been hearing "[Prefer] composition over inheritance" since I was in university (many) years ago, but Go was the first language I learned that seemed to take it to heart. Go does not have classes, so there is no inheritance. But if you embed a struct into another struct, the Go compiler does all the work of composition for you. No need to write boilerplate delegation methods. Nice.
Story Time: Encapsulation
Now that we have the nice parts out of the way, I'll dig into the parts I have problems with. I'll start with a story about my experience with Go. Feel free to skip to the "TL;DR" section below for the summary.
Back in 2016, my team was maintaining a tool that needed to make thousand HTTP(S) requests several times a day. The tool had been written in Python, and as the number of requests grew, it was taking longer and longer to run. A teammate decided to take a stab at rewriting it in Go to see if we could get a performance increase. His initial tests looked promising, but we quickly ran into our first issues.
- Unbounded resource use
- Unbounded parallelism
- Lots of boilerplate for managing channels
The initial implementation just queried a list of all URLs we needed to fetch, then created a goroutine for each one. Each goroutine would fetch data from the URL, then send the results to a channel to be collected and analyzed downstream. (IIRC this is a pattern lifted directly from the Tour of Go docs. Goroutines are cheap! Just make everything a goroutine! Woo!) Unfortunately, creating an unbounded number of goroutines both consumed an unbounded amount of memory and an unbounded amount of network traffic. We ended up getting less reliable results in Go due to an increase in timeouts and crashes.
Given the chance to help out with a new programming language, I joined the effort and we ended up finding that we had two bottlenecks: First, our DNS server seemed to have some maximum number of simultaneous requests it would reliably support. But also (possibly relatedly), we seemed to be overwhelming our network bandwidth/stack/quota when querying ALL THE THINGS at the same time.
I suggested we put some bounds on the parallelism. If I were working in Java, I'd reach for something like an ExecutorService, which is a very nice API for sending tasks to a thread pool, and receiving the results. We didn't find anything like that in Go. I guess the lack of generics meant that it wasn't easy for anyone to write a generic high-level library like that in Go. So instead, we wrote all the boilerplate channel management ourselves. Because we had two different worker pools to manage, we had to write it twice. And we had to use low-level synchronization tools like WaitGroups to manually manage resource.
Disillusioned by how gnarly a simple tool turned out, I did some searching to find out if Go had plans to add Generics. At the time, that was a vehement "No". Not only did the language implementors say it was unnecessary (despite having hard-coded generics-equivalents for things like append(), make(), channels, etc.), but the community seemed downright hostile to people asking about it.
At that point I'd already played with Rust enough to have a fair idea that such a thing was possible. In a weekend or two, I wrote a Rust library called Pipeliner, which handles all of the boilerplate of parallelism for you. Behind the scenes, it has a similar implementation to our Go implementation. It creates worker pools, passes data to them through channels, and collects all the results (fan-out/fan-in). Unlike the Go code, all that logic gets written and tested in a separate, generic library, leaving our tool to just contain our high-level business logic. Additionally, this was all implemented atop Rust's type-safe, null-safe, memory-safe IntoIterator interface. All of our application logic could be expressed more succinctly and safely, in roughly:
let results = load_urls()?
.with_threads(num_dns_threads, do_dns_lookup)
.with_threads(num_http_threads, do_http_queries);
for result in results {
// etc.
}
Go 1.18 Generics
Recently, I interviewed with a company that wrote mostly/only Go. "No problem," I thought. "I'm pragmatic. Go can't be as bad as I remember. And it's got generics now!"
To brush up on my Go, and learn its generics, I decided to port Pipeliner "back" into Go. But I didn't get far into that task before I hit a road block: Go generics do not allow generic parameters on methods. This means you can't write something like:
type Mapper[T any] interface {
func Map[Output](mapFn func(T) Output) Mapper[Output]
}
Which means your library's users can't:
zs := xs.Map(to_y).Map(to_z)
This is due to a limitation in the way that interfaces are resolved in Go. It feels like a glaring hole in generics which other languages don't suffer from. "I'm pretty sure TypeScript has a better Generics implementation than this", I thought to myself. So I set off to write a TypeScript implementation to prove myself wrong. I failed.
IMO, good languages give library authors tools to write nice abstractions so that other developers have easy, safe tools to use, instead of having to rewrite/reinvent boilerplate all the time.
TL;DR
- Despite the creators of Go and much of the Go community saying there was no need for Generics, they were finally added in Go 1.18.
- But the generics are still so basic that they can't support fairly standard use cases for generics. For example, in 2023, Go still doesn't have a standard Iterable/Iterator interface. (And the proposals at that link don't look promising to me.)
- Without good support for generics, it's difficult to write good higher-level libraries that can abstract complex boilerplate away from developers.
- As a result you either get poorer (unsafe, leaky) APIs, or developers just rewriting the same boilerplate code all the time (which is error-prone).
Other Dislikes
OK this post is already really long, so I'm just going to bullet-point some of my other complaints:
- oddly low-level for a modern GC'd language. Why do I need to
foo = append(foo, bar)instead of justfoo.push(bar)? - Interfaces are magic. Does
FooimplementBar? Better check all its methods to see if they matchBar's. You can't just declareFoo implements Barand have the compiler check it for you. (My favorite syntax for this is Rust's:impl Bar for Foo { … }, which explicitly groups only the methods required for implementing a particular interface, so it's clear what each method is for. - The automatic composition/delegation that I mentioned above is cool, but I don't think there exists a way to mark an
overrideas such so that the compiler can check it for you. - The compiler is annoyingly opinionated. If you have an unused variable, your code just won't compile. Even if the variable is unused because you've just commented out a chunk of code to debug something. Or when you're scaffolding something and want to test your progress before it's complete. Playing dumb whack-a-mole w/ errors that don't matter while experimenting is not the best use of my time. Save it for lints.
- Go isn't null-safe. Why am I getting null dereferences at runtime? Rust, Kotlin, and TypeScript have had this for a while now.
- Go has been described by Rob Pike as "for people not capable of understanding a brilliant language".
- This sort of elitism rubs me the wrong way.
- I believe you can have a "brilliant language" that enables people of many different levels to be productive. In fact, having tools to make safe APIs means that people with more interest/time can write libraries in that language that save others time and duplicated effort.
Deno Embedder
I've really been enjoying writing code in Deno. It does a great job of removing barriers to just writing some code. You can open up a text file, import some dependencies from URLs, and deno run it to get stuff done really quickly.
One nice thing is that Deno will walk all the transitive dependencies of any of your code, download them, and cache them. So even if your single file actually stands on the shoulders of giant( dependency tree)s, you still get to just treat it as a single script file that you want to run.
You can deno run foo.ts or deno install https://url.to/foo.ts and everything is pretty painless. My favorite is that you can even deno compile foo.ts to bundle up all of those transitive dependencies into a self-contained executable for folks who don't have/want Deno.
Well... almost.
This doesn't work if you're writing something that needs access to static data files, though. The problem is that Deno's cache resolution mechanism only works for code files (.ts, .js, .tsx, .jsx and more recently, .json). So if you want to include an index.html or style.css or image.jpg, you're stuck with either reading it from disk or fetching it from the network.
If you fetch from disk, deno run <remoteUrl> doesn't work, and if you fetch from the network, your application can't work in disconnected environments. (Not to mention the overhead of constantly re-fetching network resources every time your application needs them.)
In FeoBlog, I've been using the rust-embed crate, which works well. I was a bit surprised that I didn't find anything that was quite as easy to use in Deno. So I wrote it myself!
Deno Embedder follows a pattern I first saw in Fresh: You run a development server that automatically (re)generates code for you during development. Once you're finished changing things, you commit both your changes AND the generated code, and deploy that.
In Fresh's case, the generated code is (I think?) just the fresh.gen.ts file which contains metadata about all of the web site's routes, and their corresponding .tsx files.
Deno Embedder instead will create a directory of .ts files containing base64-encoded, (possibly) compressed copies of files from some other source directory. These .ts files are perfectly cacheable by Deno, so will automatically get picked up by deno run, deno install, deno compile, etc.
I'm enjoying using it for another personal project I'm working on. I really like the model of creating a single executable that contains all of its dependencies, and this makes it a lot easier. Let me know if you end up using it!
My New ASUS Router Wants To Spy On Me
After a recommendation from coworkers, and reading/watching some reviews online, I decided to get a new router. I purchased the "ASUS Rapture GT-AXE11000 WiFi6E" router in particular for its nice network analytics and QoS features.
On unpacking and setting up said router, I'm disappointed to find that the features I purchased the router for require that I give network analytics data over to a third-party.
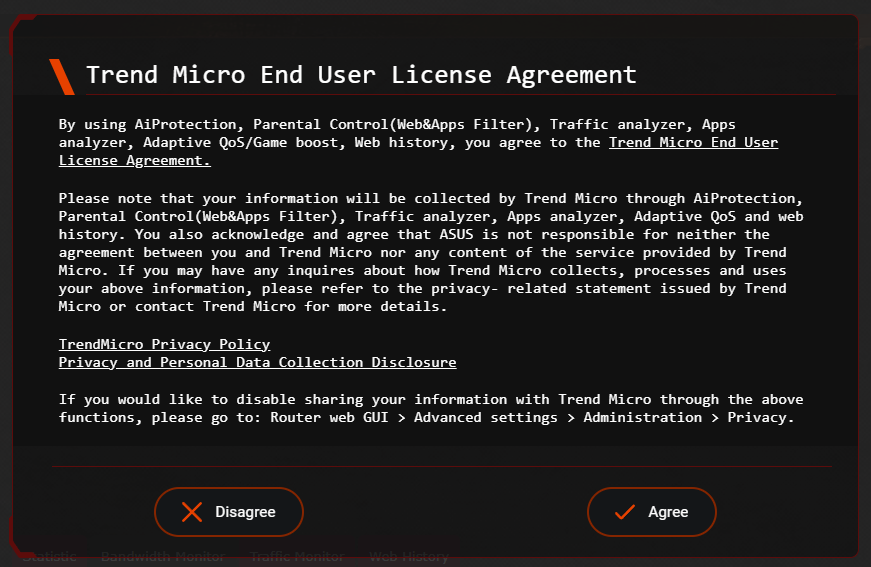
The last line of that popup says:
If you would like to disable sharing your information with Trend Micro through the above functions, please go to: Router web GUI > Advanced settings > Administration > Privacy
For a brief few seconds I was naive enough to think that the issue was just that this behavior was opt-out instead of opt-in. So I headed over to the Privacy settings to opt out.
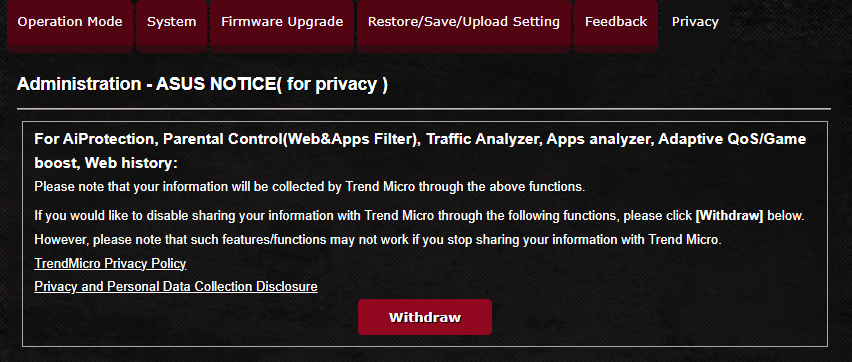
However, please note that such features/functions may not work if you stop sharing your information with Trend Micro.
"May not work" my ass! If you withdraw consent it just disables the features entirely, and then tells you:
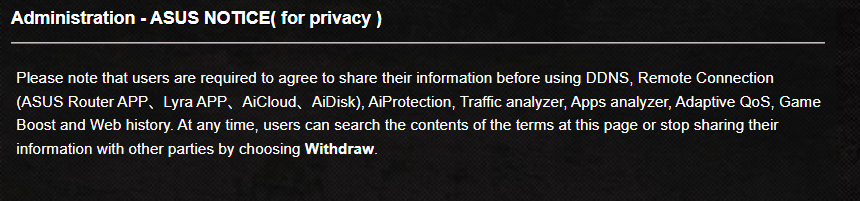
Please note that users are required to agree to share their information before using [the features that I bought this router for].
At least now (after a couple router restarts to apply settings) they're telling the truth. This is not an "option", it's a requirement.
If I go back to the "Statistic" or "Bandwidth Monitor" tabs, they're now disabled:
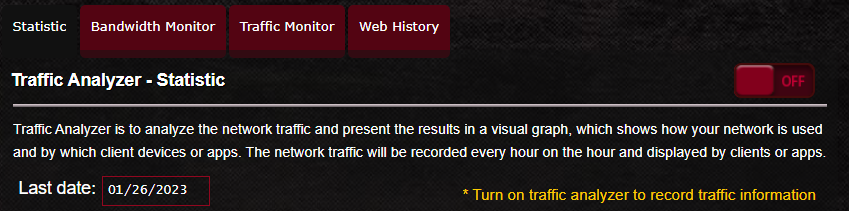
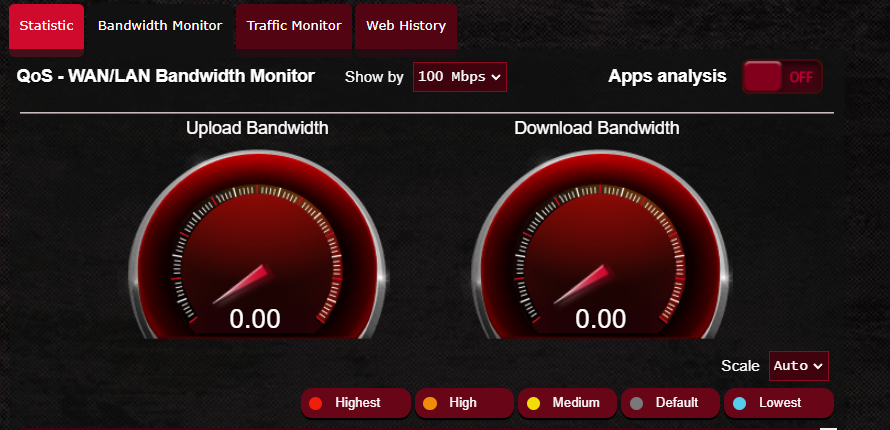
I'm considering returning this router for one that won't try to spy on me. There is NO reason for this kind of thing in my home router, a device which should be prioritizing my own security and privacy. And certainly not for features like QoS or bandwidth usage monitoring.
Does anyone have recommendations? I want something that:
- Has good network analytics so that when network issues occur, I can determine if it's due to one of my devices, or my ISP.
- Good QoS (preferably one that can adjust to varying bandwidth availability throughout the day without me having to constantly toggle bandwidth caps)
- Doesn't require consenting to third-party data collection.
I do not trust myself to write software without some form of type checking. And I prefer more typing (ex: nullability, generics) when it is available.
This comes from a long history of realizing just how many errors end up coming down to type errors -- some piece of data was in a state I didn't account for or expect, because no type system was present to document and enforce its proper states.
Relatedly, I trust other programmers less when they say they do not need these tools to write good code. My immediate impression when someone says this is that they have more ego than self-awareness. In my opinion, it's obvious which of those makes for a better coworker, teammate, or co-contributor.
Fixing your code before the weekend is like cleaning your house before you go on vacation. So much nicer to come back to. 😊
Me: I dislike that the usual software engineer career path is to move into management. I just want to write cooode!
Also me: (leading standup today, being taskmaster, making sure we capture details into tickets, unblock people, shuffle priorities from Product Mgmt, volunteering to help other devs w/ something they're stuck on) I am actually quite good at this.
😑
YAGNI
YAGNI. AIYAGNI,YWKWYNUYNI.
Not (Yet) Banned: FeoBlog
So Twitter came out with a great new feature today: You're not allowed to link to other social media web sites.
What is a violation of this policy?
At both the Tweet level and the account level, we will remove any free promotion of prohibited 3rd-party social media platforms, such as linking out (i.e. using URLs) to any of the below platforms on Twitter, or providing your handle without a URL:
- Prohibited platforms:
- Facebook, Instagram, Mastodon, Truth Social, Tribel, Post and Nostr
- 3rd-party social media link aggregators such as linktr.ee, lnk.bio
It's a laughable attempt to stop the bleeding of people fleeing to other social networks, and it's going to Streisand Effect itself into the (figurative) Internet Hall of Fame. Most of the point of Twitter for many is finding and posting links to interesting stuff online.
What's next, a ban on "free promotion of prohibited 3rd-party news sources" that point out what a ridiculous policy this is? (Though, I suppose that's not far from what they're already doing -- banning reporters who unfavorably cover Musk.)
FeoBlog is not yet banned, of course, because it's not on anyone's radar. What can I do to get some more users and get it noticed?
If you want to give it a try, it's open source software, so you can download it and run your own server. Or, if you don't want to bother with all that, ping me and I'll get you set up with a free "account" on my server. :)
AWS Lambdas: WTF
I've used AWS's SQS at several companies now. In general, it's a pretty reliable and performant message queue.
Previously, I'd used SQS queues in application code. A typical application asks for 1-10 messages from the SQS API, receives the messages, processes them, and marks them as completed, which removes them from the queue. If the application fails to do so within some timeout, it's assumed that the application has crashed/rebooted/etc, and the messages go back onto the queue, to be later fetched by some other instance of the application.
To avoid infinite loops (say, if you've got a message that is actually causing your app to crash, or otherwise can't be properly processed), each message has a "receive count" property associated with it. Each time the message is fetched from the queue, its receive count is incremented. If a message is not processed by the time the "maximum receive count" is reached, instead of going back onto the queue, it gets moved into a separate "dead-letter queue" (DLQ) which holds all such messages so they can be inspected and resolved (usually manually, by a human who got alerted about the problem).
That generally works so well that today we were quite surprised to find that some messages were ending up in our DLQs despite the fact that the code we had written to handle said messages was not showing any errors or log messages about them. After finally pulling in multiple other developers to investigate, one of them finally gave us the answer, and it came down to the fact that we're using Lambdas as our message processor.
So here's the issue, which you'll run into if:
- you use a lambda function to process SQS messages
- you set a reserved concurrency to limit that lambda's concurrency
Whatever Amazon process feeds SQS messages into that lambda will fetch too many messages. (I'm not sure if there's a way to tell if it was in a large batch, or lots of individual fetches in parallel, but either way the result is the same.)
Every time it does this, it increments the messages' receive counts. And of course when they reach their max receive count, they go to the DLQ, without your code ever having seen them.
This happens outside of your control and unbeknownst to you. So when you get around to investigating your DLQ you'll be scratching your head trying to figure out why messages are in there. And there's no configuration you can change that fixes it. Even if you set the SQS batch size for the lambda to 1.
If you think you might be running into this problem, check two key stats in the AWS console: the "throttle" for the lambda, and the DLQ queue size. If you see a lambda that suddenly gets very throttled which correlates with lots of messages ending up in your DLQ, but see no errors in your logs, this is likely your culprit.
It seems crazy that it works this way, and seemingly has for years. AWS's internal code is doing the wrong thing, and wasting developer hours across the globe. Ethically, there's also the question of whether you're getting billed for all of those erroneous message receives. But I'm mostly worried about having a bad system that is a pain in the ass to detect to work around.
Time Travel
Me, minutes before a meeting: Just one more line. One more line of code.
(15 minutes later, seeing a clock): Dangit, I'm late for my meeting.
Habits
Me: "Why do I put the cap back on my water bottle after every sip? This is annoying even to myself."
Also me: Knocks over the full bottle I just minutes before had placed between me and my keyboard and yet had somehow forgotten existed.
(Thankfully, the cap was on! 😆)
FeoBlog & Deno
For a while I'd been maintaining 2 versions of the FeoBlog TypeScript client:
- The "main" one, in Node.js, used by the web UI.
- A port of that code to Deno.
But maintaining two codebases is not a great use of time. So now the Deno codebase is the canonical one, and I use DNT to translate that into a node module, which I then import into the FeoBlog UI, which you are probably using right now to read this post. :)
A Phone Number is a Liability
Is it weird that I'm starting to feel like having a phone number is not worth it?
First, I use actual phone conversations VERY rarely. If I'm home and want to have a voice conversation with someone, I usually use VoIP (usually: FaceTime Audio) because it has higher quality than cell phone calls. If I'm out and about and want to communicate meeting time/place with someone, I'm going to send (or expect) a text message. So there's the question about whether it's worthwhile continuing to pay for a service that I don't use.
But the real problem is that modern apps and online services use your phone number as if it's a unique ID. If you give some organization your phone number, they'll definitely use it to uniquely identify you. Possibly to third parties.
And, even if you don't give them your phone number directly, since apps can slurp your contact info from any of your friends' contact lists, they've still got it.
And if companies can store this data about you, that data can get hacked and leaked. "HaveIBeenPwned" recently added phone numbers to their search because it's become such a concern.
If you worry about giving out your Social Security number, you should probably worry just as much about giving out your phone number. To companies or your friends.
This doesn't even touch on the problem of spam/phishing/fraudulent calls, which is another real problem w/ the phone system.
So, despite having the same phone number since 1998, I'd love to get rid of mine. Unfortunately, I can't yet because so many systems (ex: banks, messaging apps) do use it to identify you.
Plus, imagine you give up (or just change) your phone number. Now your old number is available for re-use. If someone were to claim it, they could then use it to impersonate you on any systems that haven't been updated with your new (lack of) phone number.
Happy Thanksgiving
I’m thankful for when the cat comes and gets me to come to bed, as if to say: “uh? Hey. I’m sleepy and I need some warm legs to curl up on. Can you get in bed already?” ❤️
So recently Elon has:
- Removed twitter identify verification (blue checkmarks are now meaningless?)
- Shut down 2FA
- Removed the information about what app someone tweeted from.
It sure is starting to seem like he paid a lot of money to delegitimize it as a communication platform.
Guess you can't get "cancelled" if people and bots are indistinguishable.
The weather finally got decently cold and we turned on the heat in the new house. Woke up at 3:15am broiling in my own bed. It turns out the previous owner had programmed the thermostat to go up to 75°F at some point in the night.
75!? I barely let the house get that warm during the summer! So I’m currently in the living room with the sliding door to the back patio cracked so I can cool off. 🥵
IDE Inlay Hints
Am I weird in disliking inlay hints?
They're those little notes that your IDE can add to your code to show you what types things are, but they're not actually part of your source code. For an example, see TypeScript v4.4's documentation for inlay hints.
My opinion is that:
- for well-written code, they fill my screen with redundant noise that makes it more difficult to see the simple code in front of me.
- for poorly-written code, they're a crutch that you can rely on instead of refactoring the code to be more readable and less fragile.
As an example, take this code:
function main() {
console.log(foo("Hello", "world"))
}
// Imagine this function is in some other file, so it's not on the same screen.
function foo(target: string, greeting: string) {
return `${greeting}, ${target}!`
}
If you're looking at just the call site, there's a non-obvious bug here because the foo() function takes two arguments of the same type, and the author of main() passed them to foo() in the wrong order.
Inlay hints propose to help with the issue by showing you function parameter names inline at your call site, like this:
function main() {
console.log(foo(target: "Hello", greeting: "world"))
}
(target: and greeting: are added, and somehow highlighted to indicate that they're not code.)
Now it's more clear that you've got the arguments in the wrong order. But only if you're looking at the code in an IDE that's providing those inlay hints. If you're looking at just the raw source code (say, while doing code review, or spelunking through Git history), you don't see those hints. The developer is relying on extra features to make only their own workflow easier.
Without inlay hints, it's a bit more obvious that, hey, the ordering here can be ambiguous, I should make that more clear. Maybe we should make foo() more user-friendly?
Lots of languages support named parameters for this reason. TypeScript/JavaScript don't have named parameters directly, but often end up approximating them with object passing:
function foo({target, greeting}: FooArgs) {
return `${greeting}, ${target}!`
}
interface FooArgs {
target: string
greeting: string
}
Now the call site is unambiguous without inlay hints:
foo({greeting: "Hello", target: "world"})
And, even better, our arguments can be in whatever order we want. (This syntax is even nicer in languages like Python or Kotlin that have built-in support for named parameters.)
The prime use of these kinds of hints is when you're forced to use some library that you didn't write that has a poor API. But IMO you're probably still better off writing your own shim that uses better types and/or named parameters to operate with that library, to save yourself the continued headache of dealing with it. Inline hints just let you pretend it's not a problem for just long enough to pass the buck to the next developers that have to read/modify the code.
Is Windows 11 Just This Slow?
I have a desktop gaming machine that runs Windows 11. It's not bad at games but it's so slow at things like, opening apps, opening settings, etc.
Is Windows 11 just this slow, or is something wrong?
It's so bad that I ran winsat formal to see if my nvme "hard drive" was somehow misconfigured:
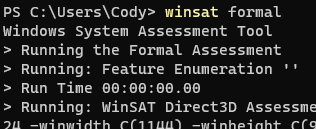
Results:
> Run Time 00:00:00.00
> Run Time 00:00:00.00
> CPU LZW Compression 1139.80 MB/s
> CPU AES256 Encryption 15057.26 MB/s
> CPU Vista Compression 2834.34 MB/s
> CPU SHA1 Hash 10656.56 MB/s
> Uniproc CPU LZW Compression 100.19 MB/s
> Uniproc CPU AES256 Encryption 986.78 MB/s
> Uniproc CPU Vista Compression 250.19 MB/s
> Uniproc CPU SHA1 Hash 774.01 MB/s
> Memory Performance 29614.11 MB/s
> Direct3D Batch Performance 42.00 F/s
> Direct3D Alpha Blend Performance 42.00 F/s
> Direct3D ALU Performance 42.00 F/s
> Direct3D Texture Load Performance 42.00 F/s
> Direct3D Batch Performance 42.00 F/s
> Direct3D Alpha Blend Performance 42.00 F/s
> Direct3D ALU Performance 42.00 F/s
> Direct3D Texture Load Performance 42.00 F/s
> Direct3D Geometry Performance 42.00 F/s
> Direct3D Geometry Performance 42.00 F/s
> Direct3D Constant Buffer Performance 42.00 F/s
> Video Memory Throughput 279385.00 MB/s
> Dshow Video Encode Time 0.00000 s
> Dshow Video Decode Time 0.00000 s
> Media Foundation Decode Time 0.00000 s
> Disk Sequential 64.0 Read 4159.90 MB/s 9.5
> Disk Random 16.0 Read 1007.15 MB/s 8.8
> Total Run Time 00:00:11.67
When it can read a Gagabyte per second when doing random access, I don't think the disk is the problem. The CPU is an "AMD Ryzen 7 3700X 8-Core Processor" at 3.59 GHz, which also shouldn't be a problem.
Anybody have tips beyond "LOL don't run Windows"?
FeoBlog Upgrades
Well, I started this morning fixing a minor bug in FeoBlog. But then the GitHub Action build failed which sent me down a day-long rabbit hole that ended up with me upgrading from ActixWeb v3 to v4.
It's a bit disappointing because Rust is in theory not supposed to break backward compatibility. But I guess some bits of their API leaked and then got used by libraries I was using.
Not really what I had planned for my Sunday but glad to be on newer versions of things, I guess? 😅
Cody Casterline updated their profile.
Silly me for reading this title and thinking this would have some good advice along the lines of:
- "Bring Your Whole Self" is good in theory. Making women and minorities feel welcomed/respected in workplaces that have traditionally not done so is a good goal.
- However, in reality, HR is not your friend.
- Despite "Bring Your Whole Self" posturing from companies, women and minorities are still at risk of repercussion when they actually do that in ways that make their white/male/cis/het/conservative/neurotypical coworkers uncomfortable.
But no. Trust the NYT to share the viewpoint from some Old/Big Money HR Handbook:
That’s right! Defy the latest catchphrase of human resources and leave a good portion of you back home. Maybe it’s the part of you that’s grown overly attached to athleisure. The side that needs to talk about candy (guilty). It could be the getting-married part of you still agonizing over whether a destination wedding is morally defensible in These Times.
Leave those things behind and I promise: No one in your workplace will miss them.
This comes off as: "Please don't talk about anything outside of work. I would prefer to view you as a cog (or in HR terms: "resource") rather than a human being."
[BYWS] dovetails with fortified corporate diversity, equity and inclusion (D.E.I.) programs. Both purport to make employees feel comfortable expressing aspects of their identity in the workplace, even when irrelevant to the work at hand.
Comfort sure sounds nice.
"You namby-pamby youngsters! How dare you want a comfortable working environment!"
So here’s an alternative: Let’s everyone bring only — or at least primarily — the worky parts. [...] It’s that old-fashioned thing we used to call “being professional.” Heck, it’s the you you were for your entire corporate history, until the prevailing H.R. doctrine abandoned buttoning things up.
The problem is that "being professional" used to be decided by "the good ol' boys" so used to mean things like:
- Women must wear makeup and skirts, and not acknowledge that they have families at home.
- Black hair styles are "not professional".
- Definitely no queers.
- Or non-Christians.
D.E.I. & BYWS are meant to counter those.
While I'm wary of it (because companies may espouse it as a value, but then not actually follow through) I'd much rather work at a company that claims to be inclusive rather than one that doesn't!
Anyway, this is just another reminder that I need to unfollow NYT. I think I'll do that now.