jsonstein@masto.deoan.org ("Jeff Sonstein") wrote:
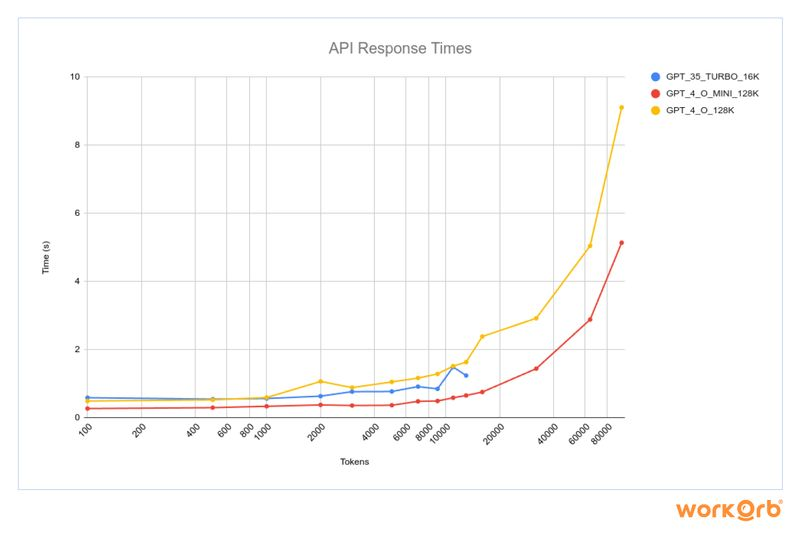
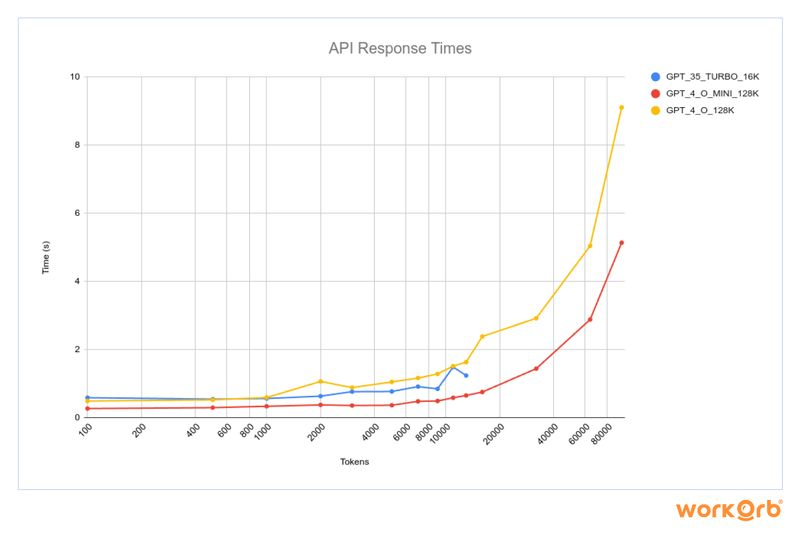
latency kills. switching models to see if I can find flatter latency as an okay tradeoff for capability
from gpt-4o to gpt-4o-mini last month, and to gpt-3.5-turbo now. hope to flatten the latency curve
{kind=link}
{kind=link}